The npm blog has been discontinued.
Updates from the npm team are now published on the GitHub Blog and the GitHub Changelog.
New Powerful Machines
TLDR
- we have had a lot of downtime in the last 2 days, and even when we were up, publishes were unacceptably slow
- we have thrown a TON of hardware at this problem
- things should be much faster and more reliable now
Monday sucked
Our uptime yesterday sucked. Here’s a pretty graph, courtesy of Fastly’s nifty analytics (these numbers are requests per minute, Pacific time zone):
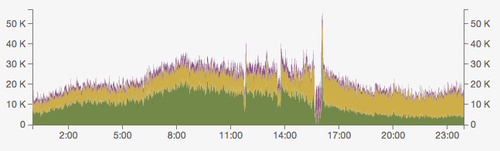
This pattern is mostly normal – peak time is 9am, and there’s usually another spike in mid-afternoon. But there are three clearly-visible events:
- 10-minute outage of our binary store caused by a maintenance operation at Manta, the service at Joyent where we store all the package binary files.
- 15-minute outage again by Manta, who have now stopped doing maintenance.
- 30-minute outage caused by the AWS us-west-2 region falling over.
Fixing the Monday things
To address the dependency on Manta, we are nearly done creating a secondary store for the binaries, so that we have them in two data centers in rotation at all times (we already have offline backups of the packages). This should improve the reliability of package data.
The AWS outage caught us by surprise – we thought we had enough capacity to handle a DC-sized outage, but growth in traffic has been such that we didn’t. So today we spun up yet more capacity, in a third datacenter, so that we can only lose 33% of our capacity at a time.
Publishing has sucked recently
Before and after these major events, we were still seeing a small but continuous number of HTTP 503s when users attempted to publish – small as a percentage of total traffic, because we are very read-heavy, but very significant, since people publishing packages is what makes npm useful. The root cause of this was an architectural problem, like so:
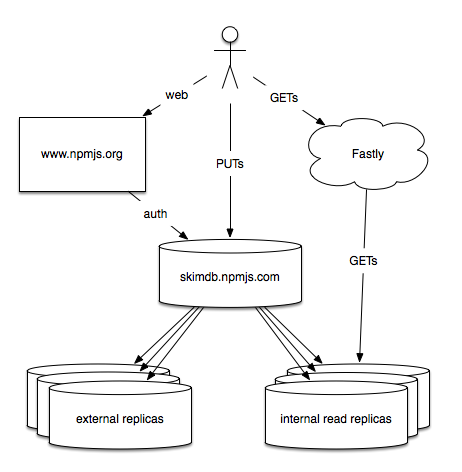
skimdb.npmjs.com was both our internal write master, our host for people running third-party replicas of the registry, and our host for internal replicas of the registry used to feed Fastly, our CDN. Also, because of the way our authentication works right now, website logins (and we have a lot of web visitors) also hit that box. skimdb.npmjs.com is a pretty hefty piece of hardware, and back in the old days (a month ago) it was fine doing all four of these tasks. Now, not so much. It was running at continuously elevated load, was super slow, and was throwing a ton of errors, even after we upped the size of the hardware a couple of times. This sucked.
A tragedy of the commons
To the best of our knowledge the big problem was those external replicas. Because we want the registry to be as open as possible, we allow anyone to create their own copy of the npm registry by replicating from skimdb.npmjs.com. Unfortunately, Couch lacks a way to rate-limit external replicas, and there are quite a lot of them now. It slowed the box down. And of course, when advanced users get frustrated with the registry being slow, one of the first things they think to do is create a local replica, which makes it even slower.
Operation Throw Hardware At The Problem
Luckily, this is the best kind of systems problem to have, the one that can be solved by adding more hardware. Here’s what we have now:
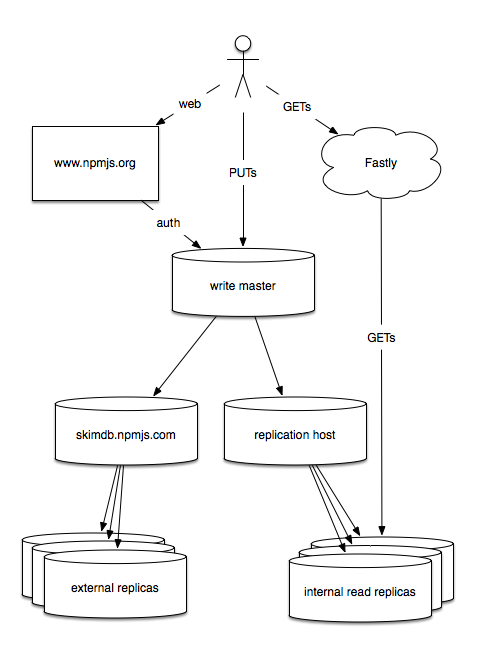
The new write master is a gigantic machine, twice the size of anything we’ve used before. It is crazy fast. And right now it is doing almost nothing. It still handles logins for the website, but that’s going to change. It handles your publishes (those are the PUTs), and it has exactly two replication clients: the original skimdb.npmjs.com, which now only serves external clients, and a new, internal replication host, which handles our internal replicas. And that’s it. In the coming weeks, if it continues to work well, we may give it a few more replicas (that replication host is a single point of failure, which I hate, and skimdb is still under a lot of load, so we may give it some siblings).
So far so good
The new hardware got slotted into place over a few hours, starting at 10am today, and finally completed at 3pm. Since then we have seen significantly improved latency, and basically zero 503s (less than 0.001% of requests). We’re going to give this new configuration a few days to bake, but we hope this will get us ahead of the load issues we’ve all been seeing the last few weeks, and give us room to grow for a while to come.
Our apologies once again for the recent downtime, and our thanks to our wonderful community for their good-natured support during this time.
But I’m still seeing 503s when I try to publish!
Try upgrading npm, like so:
npm install npm -g
Our new, distributed architecture does not always play well with older versions of the npm client when they publish. This is a known bug that is fixed in Node version 10.24 and later, or npm version 1.3.21 and later (time-wise, any version downloaded in 2014 will work). These older versions are only intermittently affected though, so you won’t necessarily see problems if you’re publishing with them.