The npm blog has been discontinued.
Updates from the npm team are now published on the GitHub Blog and the GitHub Changelog.
npm and front-end packaging
We’ve known for a while that front-end asset and dependency management is a huge use-case for npm and a big driver of Node.js adoption in general. But how big, exactly? It’s a hard question to answer. The list of most-downloaded packages on npm is not very helpful: packages like async, minimist and request are the bread-and-butter packages that are depended upon by thousands of other packages, so of course they get installed and downloaded all the time as part of the installations of those packages.
A more interesting and revealing question is: what packages do people explicitly install? By which we mean, how many times did somebody (or some robot) actually run the command npm install thispackage? We recently started plugging our log data into Jut, which has made it easy and quick to answer these questions for the first time. The resulting list of the top 50 explicitly-installed npm packages is very different and very interesting. 32% of the packages in the top 50 (and 50% of the actual downloads) are front-end tools or frameworks, with Grunt, Bower and Gulp leading the pack (mobile is also a huge use-case, and we’ll be talking about it in a later blog post). Plus, usage of all these packages is growing steadily:
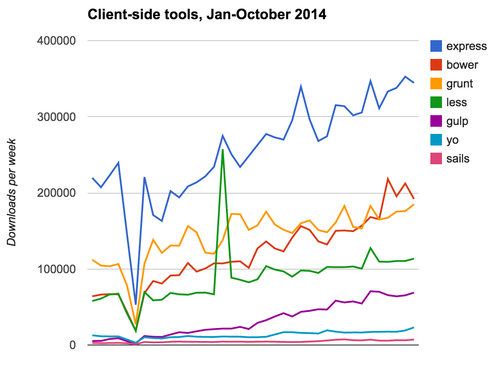
The other way we know front-end is a huge use-case is that we get a lot of questions (and issue reports) from users of npm and web developers about how best to use npm to manage client-side dependencies. These questions often have some incorrect assumptions that are strange to us, so let’s be big and bold about refuting them:
1. “npm is only for CommonJS!”
Not true. npm would like to be the package manager for JavaScript, so if it’s JavaScript related, the npm registry is a good place to put it. Node.js provides a CommonJS-esque module environment, but npm has no feelings on the matter.
2. “npm is only for server-side JavaScript!”
Also not true. Your package can contain anything, whether it’s ES6, client-side JS, or even HTML and CSS. These are things that naturally turn up alongside JavaScript, so put them in there.
npm’s code of conduct defines a very short list of things we don’t think are appropriate to put in packages (TLDR: don’t use us as your database, or your media server) but if in doubt, just ask us on Twitter or email and we’ll be happy to weigh in.
npm’s philosophy
npm’s core value is a desire to reduce friction for developers. Our preferred way to do this is by paving the cowpaths. That is to say: we don’t like to tell you what to do. We like to find out what you’re doing, and then get the obstacles out of your way. If lots of people are doing different things, we try to avoid picking a winner until it’s obviously the best.
So, when it comes to front-end packages, where is the friction, and what are the cowpaths?
Front-end pain points
In addition to GitHub issues and users on IRC, Twitter, conferences and meetups, we’ve also spoken directly to developers on some of the bigger frontend packages like Angular and Ember (both of which are also in the top 50). They didn’t all agree on solutions but their pain points were roughly in common. Let’s look at them, and then talk about how to tackle them:
1. node_modules isn’t arranged the way front-end packages need it to be
This is a pretty obvious problem. The node_modules folder is where npm puts packages by default, to take advantage of the Node.js module loading semantics. Depending what packages you install, packages end up in different places in the tree. This works great for Node, but HTML and CSS, for better or worse, generally expect things to be in one location, like /static/mypackage. There are workarounds for this to be sure, but no first-class solution yet.
2. Front-end dependencies have different conflict-resolution needs
One of the joys of the Node module loader is that it allows you to have multiple, incompatible versions of the same module present at the same time, and the one of the joys of npm is that it puts these versions into the right places so that the version you were expecting gets loaded where you expected it. This goes a long way towards eliminating “dependency hell” and is one of the reasons Node’s “many small modules” pattern is so practical and so popular.
But front-end dependencies simply don’t work this way. If you load two versions of jQuery one will “win”. If you load two versions of the Bootstrap CSS framework they will both apply simultaneously and wreck your styling. In the future, new developments in HTML like web components and Shadow DOM may help resolve these problems, but at the moment, front-end dependencies can conflict. How do we recognize and handle that gracefully?
3. Maintaining multiple package manifests is annoying
The solution to the previous problems has been to create additional registries for front-end packages, but this has created a situation where a single project must have a package.json, a bower.json, a component.json, and so on, and edit them all every time even a minor update happens. Like all data duplication, this is tedious and error-prone.
4. Finding browser-compatible packages is a pain
npm is the registry for JavaScript, but at the moment most of what’s in the registry is Node.js. Some of those modules work when adapted for clients using modules like browserify, but some of them don’t. At the moment there’s no way to easily find out which do and which don’t without trying them out.
Front-end solutions
With those four problems in mind, let’s talk about how we can solve them.
The final problem mentioned is the easiest to tackle, and we have already started laying the groundwork for the solution: ecosystems.
Ecosystems are searchable subsets of the registry, defined by programmatically filtering all the packages in the registry according to some criteria like “works in a browser” or “runs on Windows” or “is compatible with Express” or a million other possibilities. Once launched, one ecosystem will definitely be “browserify compatible”, and other definitions of “client-side friendly” will definitely be implemented as well. We’re really optimistic that this will be a great solution, which leaves us with the first three, harder problems.
Client-side package installation and dependency resolution
The third problem – multiple sets of package metadata – is a side-effect of solutions to the first two. People have written third-party tools to solve the problems of installation and dependency resolution for client-side packaging, and while doing so they have often created their own independent package registries and metadata formats. There are a whole bunch of these solutions, each with their own pros and cons. But, as you can see from our usage data the most popular solution by far is Bower. So with apologies to the great ideas in the other package managers, we’re going to focus on what Bower does.
Bower’s solution
Bower can install packages by name, from Git URLs, or from arbitrary HTTP URLs, just like npm. Unlike npm, they are all installed into a single, flat directory structure under bower_components, e.g. if backbone requires underscore, bower install backbone puts both backbone and underscore into bower_components directly. This means referring to a component from a web app is very simple, because it will always be installed in the same place, unlike npm, where your exact install path can vary.
This flat package structure means that if you attempt to install two incompatible versions of the same library – say, jQuery 1.11.1 and 2.1.1 – they attempt to install to the same location, and conflict. If this happens, Bower asks you to manually select which one you prefer, and can optionally persist this selection to bower.json. This is nondeterministic, in that it relies on a human decision, so two people installing the same packages can end up with different sets of packages. But once you persist your selections to bower.json it is consistent – anybody installing your project will get the same packages.
The user experience is not as good as Node land, where conflicts can be resolved without user intervention. However, it addresses the concerns of front-end developers and clearly works well enough.
Reducing friction without picking a winner yet
We don’t want to get ahead of ourselves. While Bower is clearly popular, there are a lot of other packaging solutions out there right now. Browsers continue to evolve rapidly, so it doesn’t seem to us that now is the right time to bless a single way of handling front-end packaging. This is where the strategy we previously outlined in the npm command-line interface roadmap comes in.
The plan for the npm CLI is to modularize it into discrete pieces that can be used independently and programmatically, not just as part of the npm client. The underlying goal is to make it possible for other people to write tools that re-use the parts of npm that work for them, and be able to implement their own solutions for the parts that don’t, without turning npm into a gigantic ball of configuration options, switches, and lifecycle hooks.
The exact design of a modularized CLI isn’t finalized, but the big pieces would obviously include:
- a API for downloading packages from the registry
- a “cache” API that can store, read and unpack packages locally
- an installer API that places packages into your project in the right location
It’s pretty clear from what we’ve already said that any front-end package manager would probably want to use parts 1 and 2 and re-implement 3.
Building your own front-end package management using npm
If you were to build the ideal front-end package management system today, what would that look like?
Here’s the medium-term future of client-side package management as we see it:
1. Don’t run your own registry, use ours
This isn’t (just) self-interest: the feedback we get from literally everybody else running package registries right now is that they don’t want to do it anymore. It’s expensive, difficult and time-consuming to maintain the kind of uptime, performance, and user support that is required. And in any case, “hosting packages” is not the problem that client-side package managers are trying to solve. If it’s JavaScript-related, host it in npm. Once they are available, use ecosystems to create “mini-registries” within the global one, complete with custom search indexing and display characteristics.
2. Use package.json for metadata
If your tool needs metadata to make it work, put it in package.json. It would be rude to do this without asking, but we’re inviting you to do it, so go ahead. The registry is a schemaless store, so every field you add is on an equal footing to all the others, and we won’t strip out or complain about new fields (as long as they don’t conflict with existing ones).
We realize this runs the risk of creating a jumble of incompatible metadata, so be reasonable: resist the temptation to grab a generic field name like “assets” or “frontend”. Use a label specific to your application, such as “mymanager-assets” or “mymanager-scripts”. If in the future we decide to more explicitly support your functionality and give it a generic field, it’s easy to maintain backwards-compatibility with the old name.
3. Use our cache module
Unpacking, storing and caching packages is a surprisingly complicated problem at scale. Especially if you are using our registry, once it becomes available, you should be using our cache module. This will save you effort, time, and bandwidth.
4. Write your own front-end semantics
This is where your use-case differs from npm’s Node-centric behaviour, so this is the only bit you should need to write yourself. Even then, we should have some handy modules that will help you out. You could do like Bower does, and download and install front-end packages into a totally different folder and handle dependencies separately. Or you could get npm to install everything into node_modules and use a post-install or a run-time hook to resolve dependencies, or some combination of those strategies. We’re not sure the best way to go, which is why we want to encourage experimentation here.
When can I start doing this stuff?
This is always the next question once we explain this plan. The best answer is: probably next year, sometime. The work necessary to get npm there as a program has already started, but npm Inc’s first mission has to be becoming a self-sustaining entity, which is why we’re concentrating on releasing private packages first, in early 2015. After that our likely next focus will be growing the usefulness of the registry itself, and that’s where client-side packaging comes in.
What can I do right now?
It’s all well and good saying we’re going to support this stuff, but you have this problem right now! So what can you do immediately, starting today?
1. Use our registry
There’s no reason not to. It’s fast, it’s got 99.99% uptime, and it’s free for open-source projects and always will be.
2. Use package.json for metadata
Again, no reason not to. It’s your package, describe it how you want. Try to avoid duplicating data (don’t make your own “name” field) and avoid generic names, but otherwise: have at it. If you think what you’re trying to do with package.json is particularly weird or complicated, we are always available on IRC, Twitter and email if you want to run the idea past us first.
3. Tag your packages
The npm “keywords” field is somewhat under-used right now, and can be used to unambiguously claim membership or compatibility with a specific ecosystem, even before they exist. For example, I tagged a package “ecosystem:hapi” and you can search for it by that tag. This obviously isn’t as good as a real ecosystem because the automatic validation isn’t there, but it’s better than ambiguous keywords.
4. Use lifecycle scripts, and browserify
It’s not a perfect solution, but we think there is merit to exploring the idea of managing client-side assets installed by npm using lifecycle scripts. You could for instance have a “postinstall” script that moves packages installed by npm into a flat structure, and queries about dependency resolution. It’s by no means perfect, but if you’re desperate for a solution right now, we’re interested to see what you can come up with using these, and your pain points will inform the work we do in getting out of your way.
We also think browserify is amazing and under-utilized, and an end-to-end solution that worked with it automatically at install time is a really, really interesting idea (check out browserify’s sweet handbook for really great docs on how to use it effectively).
Hang in there
Front-end developers want to stop using multiple package managers. Registry owners are tired of running their registries. The current support in npm for front-end packaging isn’t good enough. We know, we agree, and we’re committed to making things better. npm loves you, front-enders, and we care about your use cases. We build our own website using npm, and have the same pain points. So keep giving us feedback and ideas. We’re working on it.
There will be a winner, eventually
One final point we think it’s important to make clear: we hope that a solution emerges that is so obvious and easy to use that we can “bless” it and either build it into or bundle it as part of npm. When we do that, we don’t want people to think we pulled a bait-and-switch where we claimed there would be an ecosystem and instead we picked a winner (we’ve seen that go wrong at other companies). There is going to be a winner: we just don’t know what it looks like yet.
If you have strong feelings about what that solution should be, building a solution that works and people use is ten thousand times more persuasive than writing a long comment on a GitHub issue about it, and also super-useful to everyone in the Node community. So go forth and build solutions, and we’ll be watching closely.