The npm blog has been discontinued.
Updates from the npm team are now published on the GitHub Blog and the GitHub Changelog.
search update: improved search in the npm CLI (and how we got here)
Over last month’s holidays, with the help of npms.io, npm introduced an improved search platform and brought it to the npmjs.com web experience. We’re really proud of how this project went: it was an opportunity to work with folks in the community and pull in an open-source solution that people love.
As we promised at the time, here are some more details about the how and the why, and an exciting announcement about bringing new search to the npm command-line tool.
a long time ago in a galaxy far, far away Oakland, California…
It turns out we’ve improved search several times in the life of the company, and the story of search, like any story about npm, is a story about the JavaScript community’s terrifyingly ridiculous growth:
- at the beginning of 2012, there were 6,000 modules in the npm registry.
- by the time npm, Inc. was formed in 2014, the growing popularity of Node.js had pushed this number to 50,000 packages.
- since 2014, the solidification of npm as a place to publish modular front-end components saw this number skyrocket to 400,000 (!) packages.
At each of the steps along the way, we’ve had to make significant changes to our search algorithm, to support the growing ecosystem.
chapter 1, 2010–2012: the early years
When the registry was just getting started, guessing a few keywords was a great way to find the module you were looking for, e.g., “http request”, “xml parser”, “node globber”.
search in the CLI
npm’s first search implementation was exclusively for the CLI. This first search implementation quite simply:
- walked all packages, both those in the registry and installed locally;
- returned any packages with
description,keywords,name, etc., matching the arguments provided tonpm ls [some key words].
That’s all there was to it: no stop-word removal, no stemming, no fancy-pants search-engine technology.
With only a few hundred packages in the registry, this worked great … for a while.
search.npmjs.org
In December 2010, just a few months after we released search for the CLI, Mikeal Rogers implemented search.npmjs.org.

Mikeal’s code introduced several improvements over the initial search implementation:
- stop word removal (removing words like “the”, “to”, “as”), and other pre-processing was applied to search queries.
- results were filtered on the server side, speeding up search times.
- search functionality was pulled into special CouchDB views, rather than
relying on the implicit
allendpoint.
search.npmjs.org was definitely a step forward for search; it also set in motion the npm website’s search drifting away from the npm CLI’s search… something that’s taken us until now to correct.
chapter 2, 2012–2014: the growth of the Node.js ecosystem
At a few hundred packages in the registry, the approach to search described above worked great, but as the ecosystem grew and users adopted the tiny module method to development, search began to fail:
- there were often several packages providing the same functionality; how could a developer differentiate among them?
- there were enough packages in the registry that the “walk ’em all, and let grep sort it out” approach was starting to slow down.
To help address this growing discoverability problem, several implementations of search grew out of the community. These third-party search sites introduced many cool innovations:
- http://nipstr.com/: first commit July 3rd 2011; introduced the idea of using GitHub statistics, e.g., stars, to rank the search results returned.
- https://nodejsmodules.org/: first commit December 24, 2012; ranked packages based on a variety of package statistics: popularity on GitHub, popularity on npm, dependency counts.
- http://node-modules.com/: first commit August 16, 2013; introduced the concept of ranking packages based on social metrics, e.g., do you follow substack?
- https://npmsearch.com/: first commit January 1st 2014; used ElasticSearch, built on top of Apache Lucene.
In 2014, npmjs.com adopted the indexer used by npmsearch.com. This significantly sped up search results, while also improving the discovery algorithm by ranking based on download counts.
This is was a major improvement to the search algorithm, and a step in the right direction, but…
chapter 3, 2014–2017: npm, Inc., explosive growth, npms.io
When npm, Inc. formed in 2014, our first goal as a company was to make the registry a stable platform that people took for granted. As we stabilized the registry, this plan paid off. More ecosystems began calling the registry home: jQuery, React, and Meteor, to name a few. Between 2014 and early 2017, this helped see the number of modules in registry climb to over 400,000! … but our search algorithm did not age well:
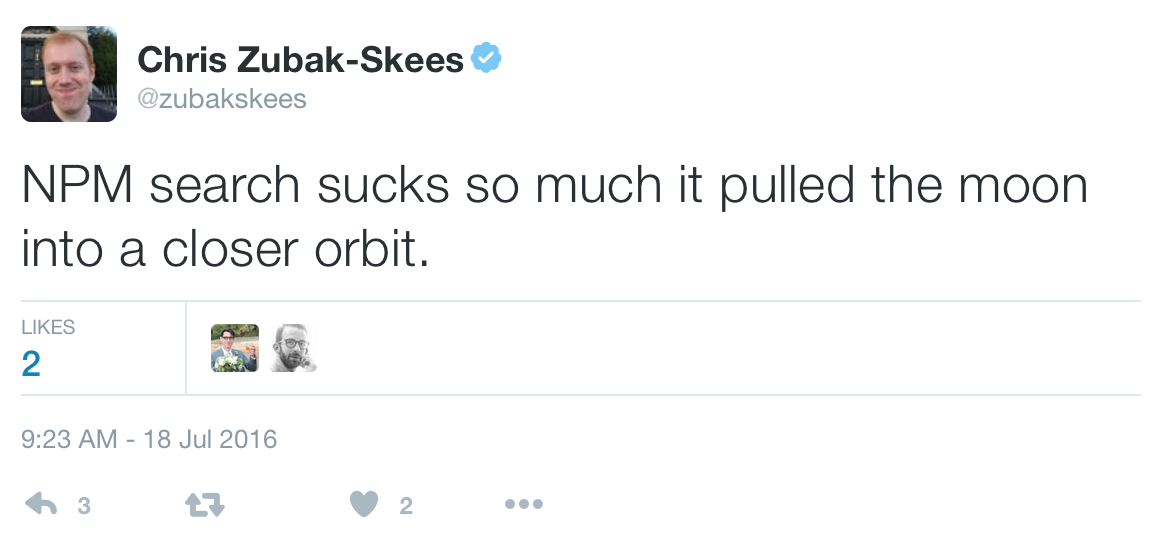
As we researched the other search engines people used in the community, it became obvious that people were impressed by the quality of the results returned by npms.io:
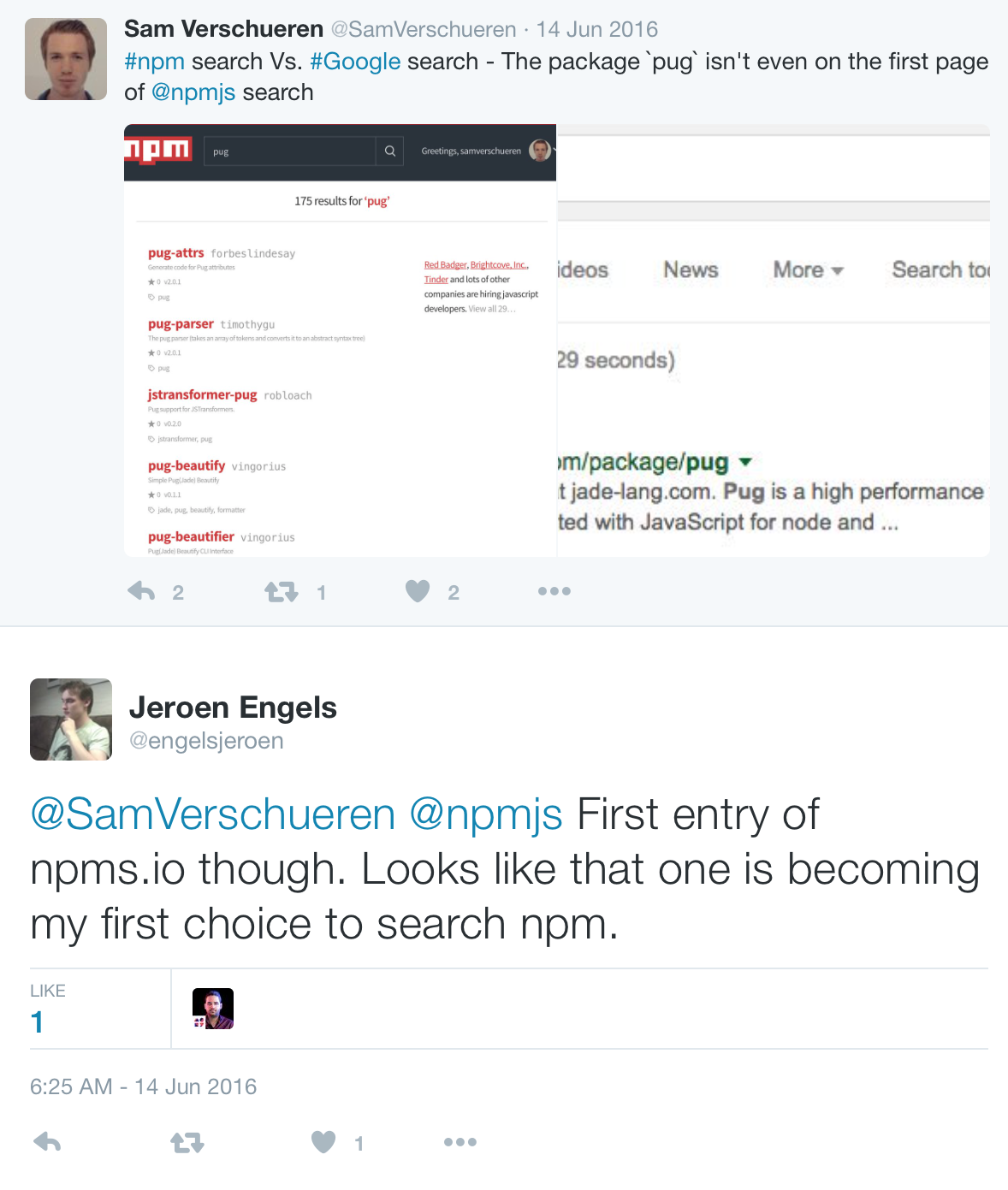
This set in motion a conversation with the folks behind npms.io, and culminated in our deciding to deploy npms.io as npm’s third-generation search.
npms.io is by far the most advanced npm search algorithm npm has ever offered. npms.io’s analyzer takes into account three categories of information in its ranking:
- Quality: Does the package have a README? Tests? Are its dependencies up to date?…
- Popularity: How many downloads does it have? How many people have starred it on GitHub?…
- Maintenance: How long does it take to close issues on GitHub? How frequently is the module released?
By ranking results based on this variety of qualities, the algorithm can surface modules that in the past might have been ignored. express is the top hit for “web framework”, for example, despite not having “web” or “framework” in its name.
So far, the response from the community has been wonderful, and we’re excited to continue working with and deploying the npms.io project.
chapter 4: the future, starting… now
What’s next for search at npm?
search improvements in the CLI
We think this is very exciting news. An upcoming update to the npm command-line tool makes it so the CLI hits the shiny new search endpoint. This will unify the website and CLI search experience for the first time since 2010. It will also make default npm search on the main registry blazing fast:
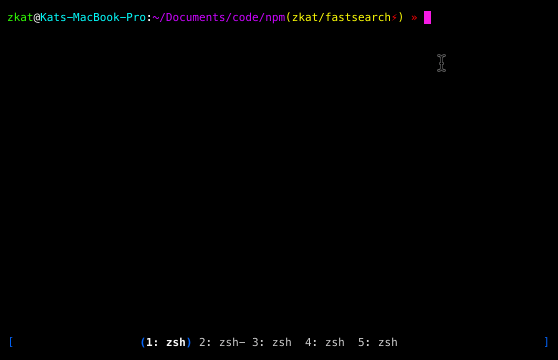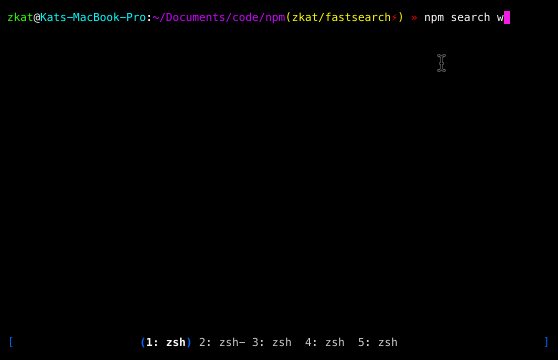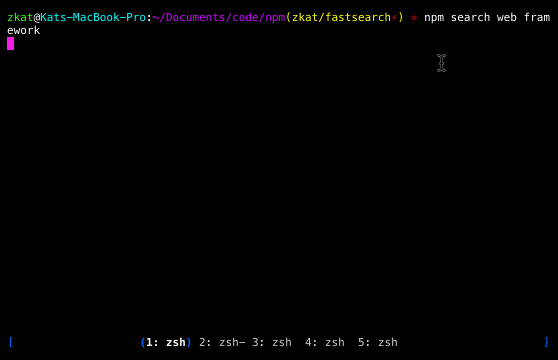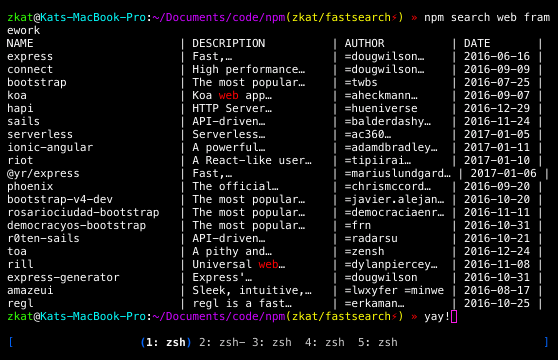
The PR is basically ready, with only a handful of remaining to-dos. Check it out.
you!
As mentioned, npms.io is an open-source project. We hope that the JavaScript community will to pitch in to continue to make our search algorithm top-notch.
Where’s feature x? What took so long? How will search work when we reach a million packages? These are good questions, and you can help with the answers. Please, join the discussion, and help make search even more amazing.